Protect your data!
Explains one of the most common reasons why invalid data is stored in your database. Learn what it is and how you can mitigate it.

The introduction of OR/M libraries and strongly typed views/view models has made many programmers switch to the dark side.
Let's fight this evil!
What evil am I talking about? Public setters in your domain/business entity (or whatever you like to call them). Public setters allow anyone at any time to modify your domain entity.
For instance, when you create an item, it's probably the repository and the controller or view model that changes it. If you have a windows service that does background processing, it will likely modify it. If you allow the user to edit the entity through a UI, you have a third place that can change the entity.
All those places have two responsibilities since the domain entity has no control over its data. First, they have to take care of their own responsibilities and ensure that the domain entity is consistent. IMHO that's not a very bright idea. How can anyone other than the domain entity know which combination of properties should be specified and when?
Just look at this terrible domain entity:
public class TodoTask
{
public string Id { get; set; }
public string Title { get; set; }
public string Description { get; set; }
public DateTime CreatedAt { get; set; }
public User CreatedBy { get; set; }
public DateTime UpdatedAt { get; set; }
public User UpdatedBy { get; set; }
public bool IsCompleted { get; set; }
public bool CompletedAt { get; set; }
public DateTime AssignedAt { get; set; }
public User AssignedTo { get; set; }
public List<UserHistoryEntry> UserHistory { get; set; }
}
public class UserHistoryEntry
{
public DateTime StartedAt { get; set; }
public DateTime EndedAt { get; set; }
public User User { get; set; }
}Ewwww. That's horrible. I can barely look at it. Give me a minute..
Ok. So what's wrong with that entity? It's not responsible for its own data. So any class that uses it can change its content without validation. Ever had to manually correct database content? This is the primary reason why.
Here is a sample method to illustrate the problem:
public class TodoController : Controller
{
[HttpPost, Transactional]
public ActionResult Edit(TodoModel model)
{
var dbEntity = _repository.Get(model.Id);
if (dbEntity.IsCompleted != model.IsCompleted)
{
if (!model.IsCompleted)
{
// Changed from completed to not completed
// error?
}
dbEntity.IsCompleted = true;
dbEntity.CompletedAt = DateTime.Now;
foreach (var user in dbEntity.UserHistory)
{
_emailService.Send(user.Email,
"Item completed",
dbEntity.AssignedTo +
" has completed item " + dbEntity.title);
}
}
if (model.AssignedTo != dbEntity.AssignedTo)
{
dbEntity.AssignedTo = model.AssignedTo;
dbEntity.AssignedAt = model.AssignedAt;
foreach (var user in dbEntity.UserHistory)
{
_emailService.Send(user.Email,
"Item (re)assigned",
dbEntity.AssignedTo +
" has been assigned to " +
model.AssignedTo);
}
}
_repository.Save(dbEntity);
}
}Take a moment and look at the code. We have whipped up a view using Visual Studio's tooling (using a strongly typed view model, edit template). Since we allow the user to edit most fields, we need to include different checks for different states and act accordingly. (It would be slightly better if that code existed in your service class instead of in the controller/VM.)
Let's fast forward one year. You now have a problem with the to-do items. For some reason, the CompletedAt date is not saved when it should. You, therefore, add a new check each time a to-do item is saved in the repository:
You check if CompletedAt is set; if not, you assign it.
That is a workaround. Those kinds of workarounds are almost always present in applications that expose all entity data to everything. It does not matter if you have a TodoService class that should handle everything for the to-do items since all other code can "fix" the entity info. Hence you WILL get those workarounds sooner or later.
Introducing the cure
Let's look at the cure. In fact, it's effortless. Make all setters private:
public class TodoTask
{
public string Id { get; private set; }
public string Title { get; private set; }
public string Description { get; private set; }
public DateTime CreatedAt { get; private set; }
public User CreatedBy { get; private set; }
public DateTime UpdatedAt { get; private set; }
public User UpdatedBy { get; private set; }
public bool IsCompleted { get; private set; }
public bool CompletedAt { get; private set; }
public DateTime AssignedAt { get; private set; }
public User AssignedTo { get; private set; }
public IEnumerable<UserHistoryEntry> UserHistory { get; private set; }
}Notice that I've changed UserHistory to IEnumerable. That's so that we don't break the Law of Demeter (and lose control over the history changes). The to-do item is now protected, but we can't change anything, and we can't build a UI. The solution to that problem is simple; We do not just want to change data; we want to take action! So let's add some methods so that we can do that.
public class TodoTask
{
public TodoTask(User creator, string title, string description)
{
// insert argument exceptions here.
CreatedBy = creator;
CreatedAt = DateTime.Now;
UpdatedBy = creator;
UpdatedAt = DateTime.Now;
Title = title;
Description = description;
}
// [... all the properties ..]
public void Assign(User user)
{
// insert argument exception here
UserHistory.Add(new UserHistoryEntry(AssignedTo, AssignedAt, DateTime.Now));
AssignedTo = user;
AssignedAt = DateTime.Now;
UpdatedAt = DateTime.Now;
UpdatedBy = Thread.CurrentPrincipal.Identity;
// hooked by the email dispatcher
// the event architecture is provided by Griffin.Container
DomainEvent.Dispatch(new ItemAssigned(this));
}
public void Complete()
{
if (IsClosed)
throw new InvalidOperationException("Item has is closed and cannot be completed");
IsCompleted = true;
CompletedAt = DateTime.Now;
UpdatedAt = DateTime.Now;
UpdatedBy = Thread.CurrentPrincipal.Identity;
DomainEvent.Dispatch(new ItemCompleted(this));
}
public void Update(string title, string description)
{
// insert argument exceptions here
UpdatedAt = DateTime.Now;
UpdatedBy = Thread.CurrentPrincipal.Identity;
Title = title;
Description = description;
DomainEvent.Dispatch(new ItemUpdated(this));
}
}Constructors
I use constructors to force mandatory data, ensuring that the item is never in an inconsistent state. It also makes it easy to spot what kind of information each entity requires.
Methods
Next, I added two methods for the two actions take can be taken on our to-do item. The data is now protected and do not have to rely on that all dependent classes would have changed the related properties correctly.
Our to-do code is, therefore, a lot less error-prone than before.
Make it a habit to make setters private if more than one property needs to be changed on a specific occasion. It ensures that your entity always is in a consistent state.
Exceptions
Notice that I also validate the state in the methods. For instance, it should not be possible to set an item as completed if it has already been marked as deleted.
Those checks are more important than you think.
It can be hard to resist removing checks like that. You probably think, "It's not so bad that a deleted item gets set as completed; what can happen?". That does not matter. If you start thinking like that, where do you end? It IS a bug. Better to have a zero-tolerance policy. Fix all bugs, no matter how small or unimportant they are.
They also help since they detect problems more early on, compared to allowing incorrect state changes.
Summary
Since we got complete control over our data, it's pretty easy to make sure it stays that way. Unit tests become more straightforward as the purpose of each method and what it does is more prominent. I tend to constantly nag about unit tests: Classes that are hard to unit test are often a likely candidate for refactoring.
As we got our methods, it's also easier to publish events for the actions (pub/sub, you can use Griffin.Framework). Those events can be used to trigger other activities in other parts of the system, giving us a more loosely coupled application.
Encapsulation is essential since it's hard to track down bugs generated due to the wrong set combination of properties. Furthermore, those bugs tend to surface later as incorrect data is stored in the database. So it might be a week or a year after the bug appears. That's why most bug fixes for that are really workarounds (you can't find the bug source, so you just "correct" the model information when you can).
A properly layered application helps you to prevent that. It doesn't matter how many layers you create, as long as the business layer is isolated and not dependent on any other layer. It helps since it allows you to write unit tests purely focused on making sure that the domain model (i.e., business layer classes) solves the business requirements (through your newly created methods). Spend some time doing it, and the unit tests will be like poems telling a part of the story.

UI design
If you follow me on Twitter, you had probably read a somewhat cryptic message a couple of weeks ago. It said something like, "make all setters private and see what it does to your UI." The point was that if you make all setters private, it forces you to use methods. It also effectively prevents you from creating CRUD applications (uuuhh, I really, REALLY hate those).
Your users might think that they want a simple CRUD app. But really. They don't. My current client is using a web-based application to be able to follow ISO2000 (a small part of it is a case management system). The edit case screen for it looks like this:
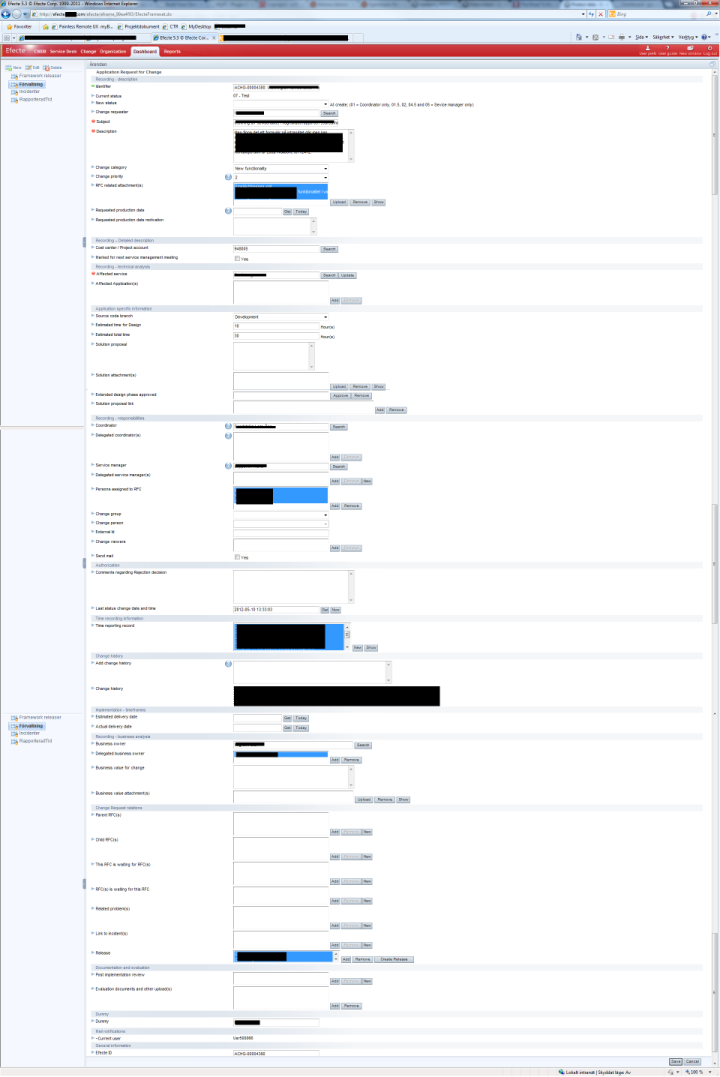
(yes, the image is from a natural production system.)
The point is that approximately 20% of the fields are used when creating the issue. 10% or less is used for each state change (the issue can have 10 different states). Research shows that presenting too much information makes it harder for the user to decide what to do. This makes the user subconsciously hostile to using the application (my own subjective conclusion based on experience). Have you ever heard "Less is more"? It's very true when it comes to UI design.
A great way to design an UI is to stop focusing on the information but on the actions instead. Don't ask the client what kind of information he want's to handle. A great starting question would be, "When you start the application, what do you want you to be able to do on the start page?". You won't get an answer that states, "I want to be able to specify title, description, creation date, and the user who created the item". But "I want to be able to create a to-do item." Don't be tempted to ask which information the user wants to specify, but ask what the minimal requirements are. Then take it from there.
Why am I ranting about this? Because changing to private setters actually helps you to create a better UI and improve the user experience. If you are using the scaffolding feature in your UI library, try to make an edit view using your domain model. How many fields does the wizard add for you? The answer is ZERO. Isn't that great? =)
Create a view (and a view model) that corresponds to each method in the model. Only specify the fields that the method takes as its arguments. Voila, you have now got a lot more user-friendly UI.
Let's look at the original to-do item edit page:
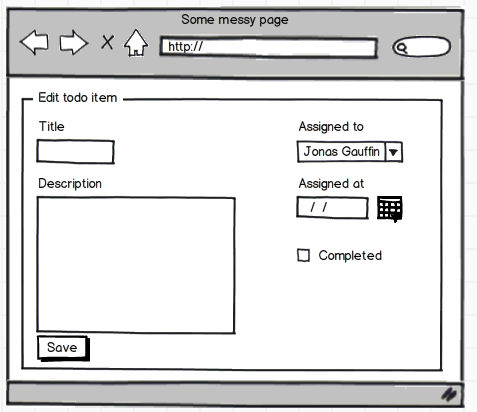
(again, it's a simple model)
We can't build our UI in the same way anymore since our methods effectively prevent us from having many edit fields. Hence we have to scrap the old edit page and refactor our UI. For example, the details page will now get some buttons instead.
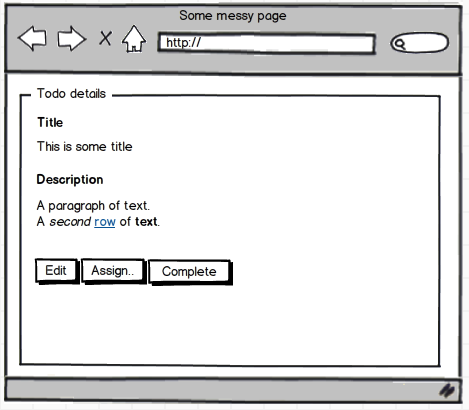
And when we press, for instance, the assign button, we get:
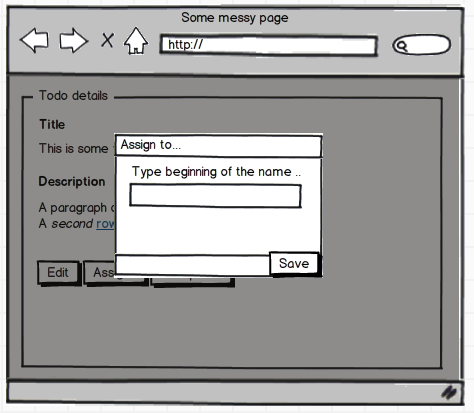
Isn't that more straightforward than before?
ORM
How do you handle domain entities in your ORM?

First of all: The OR/Ms responsibility is persistence only. The information stored in the database doesn't have to have a 1-1 relation with your domain model. You can normalize or denormalize the information to store it more efficiently or make it easier to query the data source. The point is that the entity that your OR/M uses isn't always an exact copy of your model. Be careful if you reuse the domain entity in the data layer, as you might end up with compromises that will hurt both your business and data layers.
In 99% of the cases, I use repository classes even if I'm using an OR/M. It's so that I can refactor the data source (for instance, denormalize it) or refactor the models without affecting the dependent code. And to unit test all code that loads/store data to/in the data source.
If you genuinely want to create layered applications, you have to ensure that the abstraction between the layers is intact. It will force you to write more code. That's no way around that. But the code is more loosely coupled, making it easier to maintain and extend it in the future.
However, Entity Framework (and similar OR/Ms) is quite flexible when mapping. They can handle properties with private setters. This means that you can use the business entity as the database entity in many cases. Since I use repository classes, it doesn't really matter. I might start with a 1-1 mapping but later switch to DB entities if the code diverges later.
Summary
Going back to one of the object-oriented programming fundamentals (encapsulation) doesn't just make our code less error-prone. It also forces us to think again about how we design the applications and the UI. Don't just be a code monkey using the provided scaffolding tools. Think about what those tools do to your application. Their end result might not always be a good thing.